How to Prepare Data for AI: A Complete Startup Guide

AI is only as good as the data you feed it—the better prepared the data, the better your results. As artificial intelligence continues to drive innovation and growth, knowing how to prepare data for AI has become more important than ever. If data quality is overlooked, it can easily end up being the reason an AI project fails.
Think about this: every year, bad data costs American companies over $3 trillion (according to IBM), and knowledge workers end up spending more than half their time dealing with data issues. That could mean hunting down information, fixing mistakes, double-checking for errors, or cleaning up after the fallout of unreliable data.
So how can you stay ahead? Let’s dive into the key steps, common challenges, and smart strategies behind effective data preparation for AI—helping you get your data ready to power truly impactful results.
Key Takeaways
- AI models learn from data; therefore, the quality of your data directly impacts the performance and reliability of your AI apps.
- Preparation is a multi-stage process. It involves understanding the problem, collecting, cleaning, labeling, transforming, and splitting your data. Each stage contributes to the final success.
- Scaling data preparation requires strategic planning. As your data volume grows, setting up efficient workflows and leveraging tools becomes essential.
What Is Data Preparation for AI?
AI data preparation is the process of transforming raw data into a format suitable for machine learning and AI algorithms, and it is closely tied to effective data management practices that ensure data quality, consistency, and accessibility. It includes a series of steps you take to ensure data quality, relevance, and usability for building effective AI models.
Preparing data for machine learning and AI is not a one-time task but rather an iterative process that may need to be revisited as the AI project grows and changes. Some of the situations that trigger the data prep process are when new data becomes available or your understanding of the problem deepens.
Why Does Data Preparation Matter for AI?
In its raw state, data comes from various sources: databases, sensors, web scraping, and user interactions. It can be messy, incomplete, inconsistent, and not usable for training AI models. Data preparation specialists perform cleaning, structuring, and enhancing the data, so you get an ideal input for AI algorithms to learn from and make accurate predictions or decisions.
The adage garbage in, garbage out holds particularly true when it comes to AI. The quality of your prepared data is the single most influential factor determining the performance and reliability of your AI models. Here are more effects of AI data preparation:
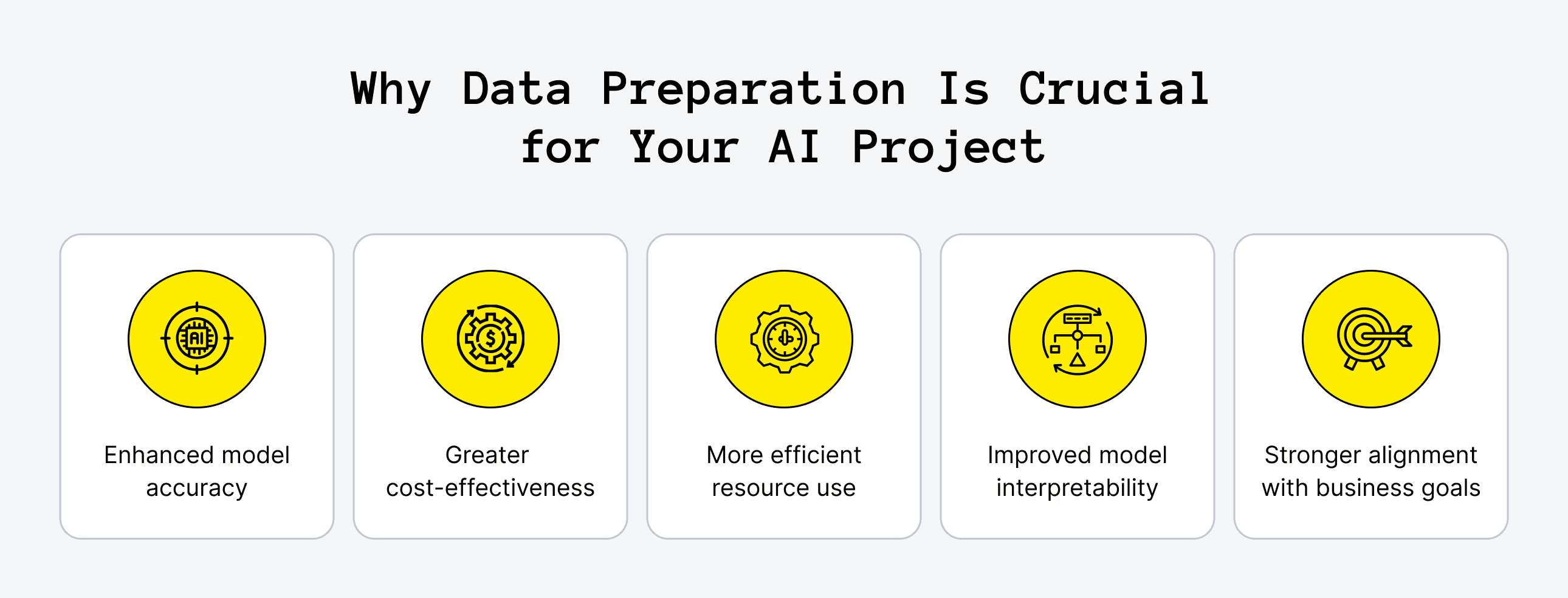
Improved Accuracy
High-quality training data leads to models with higher accuracy and better generalization to unseen data. Data preparation techniques like handling imbalanced datasets and feature scaling contribute to a model's ability to generalize.
Reduced Resource Use
When data is properly formatted and free of irrelevant information, AI models can converge faster during the training process. You save computational resources and accelerate the product development cycle.
Higher Interpretability
Clean and well-structured data helps you understand the factors influencing the model's predictions. Better interpretability helps build trust in AI systems, especially in sensitive applications. This level of transparency is especially important when developing conversational agents or aiming to build the smartest AI chatbot, where trust and clarity are key to user satisfaction.
Feature engineering, a part of data preparation, can create more meaningful input features that the model can learn from and that humans can interpret.
Higher Cost Efficiency
Investing in thorough machine learning data preparation upfront often saves significant development costs in the long run. The reason is that you reduce the need for extensive debugging and retraining of poorly performing models. It also helps minimize the risk of deploying AI systems that make inaccurate or biased predictions.
On average, proactive data quality management can reduce data-related operational costs by 10-30% in the long run. (McKinsey)
Better Alignment with Project Goals
The specific requirements of your AI project dictate the necessary data preparation steps. For example, a natural language processing project will need different data cleaning and transformation techniques compared to a computer vision project. AI project data requirements should guide the entire data preparation process.
So, in essence, how to prepare data for machine learning and artificial intelligence boils down to transforming raw and potentially chaotic data into a valuable asset that drives intelligent insights and automated processes.


How to Prepare Data for Your AI Project: A Step-by-Step Guide
Preparing data for your AI project is a systematic process with clear steps. Let's take a look at what each of them looks like.
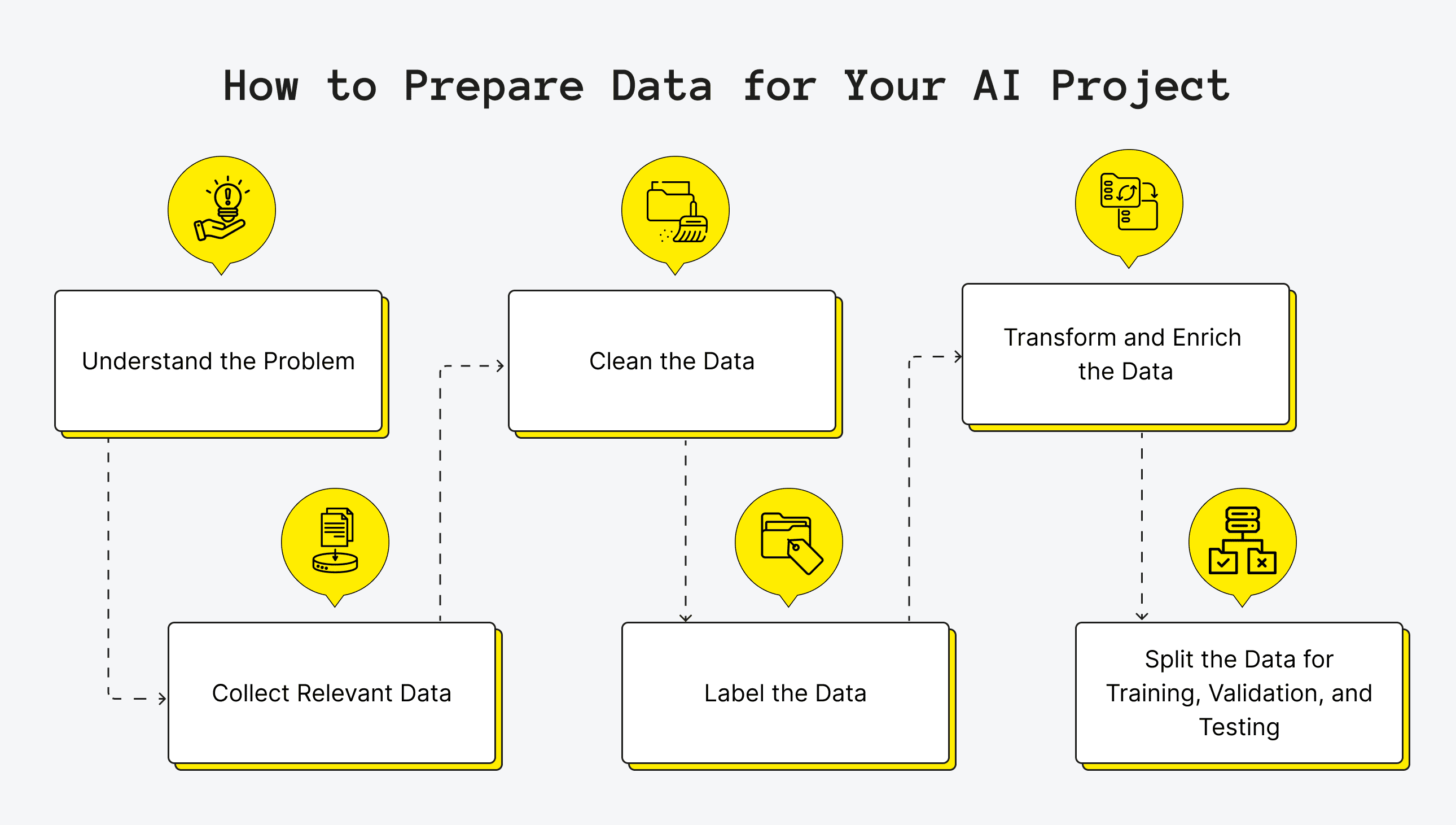
1. Understand the Problem
Before touching any data, the first step is to define the problem you are trying to solve with AI. A clear understanding will dictate the type of data you need, the feature prioritization process, and the desired output of your AI model. You'll need to answer these questions:
- What goal do you want to achieve with AI?
- What is the variable you want your AI model to predict or classify?
- What data points might influence the target variable?
- How will you measure the success of your AI model?
For example, if you aim to predict customer churn, you'll need historical data on customer behavior, demographics, and interactions with your product or service. The variable you might want to predict will be churn rate or an individual customer's probability of churn.
Among other data points that influence your churn can be some elements of your onboarding process, UX, or value that your service provides for the price customers pay.
If your model has successfully predicted churn for some customer clusters and you've been able to link it to a particular issue, you can consider it a success.
2. Collect Relevant Data
After defining your problem, it’s time to gather the data needed to train your model. This process involves several important steps:
- Find out where your data lives. Look for sources such as internal databases, CRM systems, web analytics platforms, social media third-party APIs, public datasets, or data from sensors and IoT devices. For firmographic enrichment, pull in up-to-date company data to augment internal records with company profiles, hiring signals, and tech stacks. Each source offers unique information that could be crucial for your model.
- Plan how you’ll gather the data. This might involve setting up data pipelines, querying databases, web scraping, or even buying data from reliable third-party vendors. A well-defined approach avoids gaps and saves time down the road.
- Think about how much data you need and its variety. More high-quality data generally means better model performance. Including diverse data types helps your model learn patterns and generalize beyond the training set.
- Make sure you collect data responsibly. That means following data privacy regulations like GDPR and CCPA, and establishing solid data governance policies. Ethical collection builds trust and keeps your business compliant.
For instance, if you are building a recommendation system for an e-commerce platform, you would need to collect data on user purchase history, browsing behavior, product information, and potentially user reviews.

3. Clean the Data
Raw data is rarely perfect because it often contains errors, inconsistencies, missing values, and noise that negatively impact the performance of your AI model. Data cleaning for AI is a critical step to address these issues. Sometimes, it takes up to 60% of all model engineering time to clean the data, but the result and reduced risk are worth the investment.
To start with, decide how you’ll handle missing data. Your options include:
- Deletion: Remove rows or columns with a significant number of missing values. Do this cautiously, as it can lead to loss of valuable information. A common threshold is if more than 30-50% of the values in a column are missing.
- Imputation: Fill in missing values using statistical methods (e.g., mean, median, mode) or more advanced techniques like regression imputation or using algorithms like k-Nearest Neighbors. The choice of imputation method depends on the nature of the data and the extent of missingness.
Then, identify and handle outliers. These are data points that highly deviate from the rest of the data. They can skew statistical analyses and negatively affect model training. Techniques for handling outliers include:
- Detection: Use visualization techniques (e.g., box plots, scatter plots) and statistical methods (e.g., Z-score, IQR) to identify outliers. For example, a Z-score greater than 3 or less than -3 will likely be considered an outlier.
- Treatment: Decide whether to remove outliers, transform them (such as using log transformation), or keep them depending on the context and the potential reasons for their existence.
Next, identify and correct inaccurate or inconsistent data entries, such as:
- standardizing formats for dates, times, units of measurement, and categorical variables. For example, converting all date formats to YYYY-MM-DD;
- identifying and removing or merging duplicate data entries;
- using spell-checking tools or manual review to fix errors and typos in text data.
At the final step, smooth out random errors or variations in the data that don't reflect underlying patterns. Use filtering, smoothing algorithms, or statistical methods like moving averages.
The extent of data cleaning required depends on the source and quality of your raw data. It's an iterative process, and you may need to revisit cleaning steps as you explore and understand your data better.
4. Label the Data
Data labeling for AI is the process of assigning meaningful tags or categories to your data points. You will especially want to do this for supervised learning tasks like classification (identifying cats vs. dogs in images) and object detection (locating objects within an image and classifying them).
- Define the categories or tags you need for your AI task. Ensure that the labeling guidelines are precise and unambiguous to maintain consistency. For instance, if labeling customer reviews as positive, negative, or neutral, the criteria for each category should be well-defined.
- Select appropriate tech stack and methods for labeling your data. Your options are:
- Human annotators can manually label each data point, which is time-consuming but is often necessary for complex tasks or when high accuracy is the top priority.
- Use algorithms or pre-trained models to automatically label data, with human review for verification and correction. It's much faster for large datasets.
- Outsource labeling tasks to a distributed workforce. It's cost-effective for large volumes of data but needs careful quality control.
- Implement quality control measures to make sure that the labels are consistent and accurate. You might want to have multiple annotators label the same data points and measure inter-annotator agreement (for example, using Cohen's Kappa coefficient).
- Handle imbalanced datasets. If your labeled data has an uneven distribution of classes (such as significantly more not fraud than fraud examples), you might need to employ oversampling the minority class, undersampling the majority class, or using algorithms that can handle class imbalance.
The quality of your labels impacts the performance of your supervised learning models. So, it's best to invest time and effort in creating accurate and consistent labels.
5. Transform and Enrich the Data
Transforming and enriching the data means converting it into a format that is more suitable for machine learning algorithms and maybe adding new features that can improve model performance. Here's what you have:
- Feature scaling. Many machine learning algorithms are sensitive to the scale of input features. Scaling techniques like standardization (making features have zero mean and unit variance) or normalization (scaling features to a specific range, e.g., 0 to 1) help algorithms converge faster and prevent features with larger values from dominating. The choice between standardization and normalization depends on the algorithm and the distribution of the data. Proper feature scaling is also important for multi-agent LLMs, as it ensures all agents process inputs consistently.
- Feature encoding. Machine learning models typically work with numerical data. That is why categorical features (color, city, etc.) need to be converted into numerical representations with:
- One-hot encoding. Creates binary columns for each category. Suitable for nominal categorical variables (no inherent order).
- Label encoding. Assigns a unique numerical label to each category. Use it for ordinal categorical variables (have an inherent order).
- Embedding techniques. For high-cardinality categorical features (many unique categories), embedding layers can learn dense vector representations.
- Feature engineering. This means creating new features from existing ones that might be more informative for the AI model. Two things you will need: domain expertise and creativity. What you can do:
- Create interaction terms. Combining two or more existing features, like multiplying age and income.
- Extract date or time components. Break down a timestamp into year, month, day, hour, etc.
- Create aggregate features. Calculate summary statistics (e.g., mean, max, min) over groups of data.
- Dimensionality reduction. If your data has a very large number of features, you can use Principal Component Analysis (PCA) or t-SNE to reduce the number of features but still retain most of the important information. This way, you can reduce computational cost and prevent overfitting.
- Data augmentation. For image recognition or NLP, data augmentation techniques are used to artificially increase the size of the training dataset and create modified versions of existing data (rotating, cropping, or flipping images; adding synonyms or back-translating text, etc.).
Taking this step of careful feature engineering and transformation can help improve the performance and efficiency of your AI models.
6. Split the Data for Training, Validation, and Testing
Once your data is cleaned, labeled, and transformed, you need to split it into three separate sets:
- The training set is the largest portion of the data (70-80%) and is used to train the AI model. The model learns patterns and relationships from this data.
- The validation set is a smaller portion (10-15%) used to evaluate the model's performance during training. With it, you tune hyperparameters (parameters that control the learning process) and prevent overfitting (where the model performs well on the training data but poorly on unseen data). You might iterate on your model and hyperparameters based on the validation set performance.
- The testing set is another smaller portion (10-15%) that you use to evaluate the final performance of the trained model on completely unseen data. As a result, you get an unbiased estimate of how well the model will generalize to new real-world data. The test set should only be used at the very end of the model development process.
The way you split your data matters most. For time-series data, you should maintain the temporal order. For imbalanced datasets, you might use stratified sampling to ensure that each split has a representative proportion of each class.
Common split ratios include 70/15/15 or 80/10/10 for training, validation, and testing sets, respectively, but you can adjust them based on the size of your dataset.
Need a hand with generative AI development?
Upsilon is a reliable tech partner with a big and versatile team that can give you a hand with creating an AI solution.

Challenges in Data Preparation for AI
Despite its importance, preparing data for AI is a challenging process that, as we've talked about, can take up to 60% of a data scientist's time.
Data Quality Issues
You might have noticed already that cleaning the data means sealing with missing values, noisy data, inconsistencies, and errors. It's a time-consuming process that requires much effort. Identifying and resolving these issues often requires domain expertise and careful analysis.
As reports show, poor data quality for AI models is one of the primary reasons for the failure of artificial intelligence projects.
Data Volume and Velocity
Another reason AI models fail is when they have little to no data or too much data. With the rise of big data, preparing massive datasets that are constantly being generated is a significant challenge. Traditional data preparation methods may not be scalable enough to handle the volume and velocity of data in real-time.
Startups dealing with large volumes of data need to invest in efficient data pipelines and processing AI frameworks. Those who don't have enough data but still go for AI risk to deliver extremely biased and incompetent algorithms.
If you don't possess enough data, the artificial data generation techniques we've covered can help. There's no single magic number for how much original data you need to synthesize new data. However, you need enough data to accurately capture the true underlying patterns and relationships in your dataset.
Data Integration
AI projects often require data from multiple disparate sources. Integrating these datasets, which may have different formats, schemas, and quality levels, is a complex task. You need to ensure data consistency and create a unified view of the data.
If we speak about big data preparation for AI, you'll likely need to invest in custom automated data integration.
Data Complexity and Variety
Modern datasets go with a wide variety of data types (structured, unstructured, semi-structured) and formats (text, images, videos, audio). You need tools to prepare such diverse data for AI for each data type. In many cases, intelligent document data capture helps convert messy, multi-format inputs into structured fields your models can use.
For example, preparing text data for NLP involves tokenization, stemming, and lemmatization, while preparing image data involves resizing, normalization, and augmentation.
Data Privacy and Security
Handling sensitive data requires strict adherence to privacy regulations and security protocols. You will choose between data anonymization, pseudonymization, and other privacy-preserving techniques during the data preparation process. Integrating an OTP service ensures that only verified users can access sensitive or anonymized data.
This process adds extra complexity, especially if you manage information from multiple regions.


Lack of Standardized Processes
Unlike software development, data preparation for AI lacks standardized processes and best practices, especially when it comes to a unique combination of data sources, types of information, and goals.
It can be difficult to reproduce results and scale the process for a unique project.
Skill Gaps
Data cleaning and preparation can easily consume over 60% of your time if your team lacks the right mix of technical skills—such as data wrangling, programming, statistical analysis, and domain expertise.
Fortunately, there are several ways to address these gaps. You might hire dedicated specialists to join your startup in-house, but for many, a faster and more cost-effective solution is to outsource data tasks to a specialized product development studio with proven expertise in data engineering and AI. This way, you gain access to top talent without sacrificing quality or speed.
Once you've overcome these challenges, have the right people and processes in place, and are ready to scale, you'll want to make your data preparation even more effective. Let's look at how you can achieve this.
How to Scale Your Data Preparation Process
As your AI initiatives grow and the volume of data you handle increases, it's good if you already have scalable data preparation processes in place. Below are some strategies for how to scale your data preparation process:
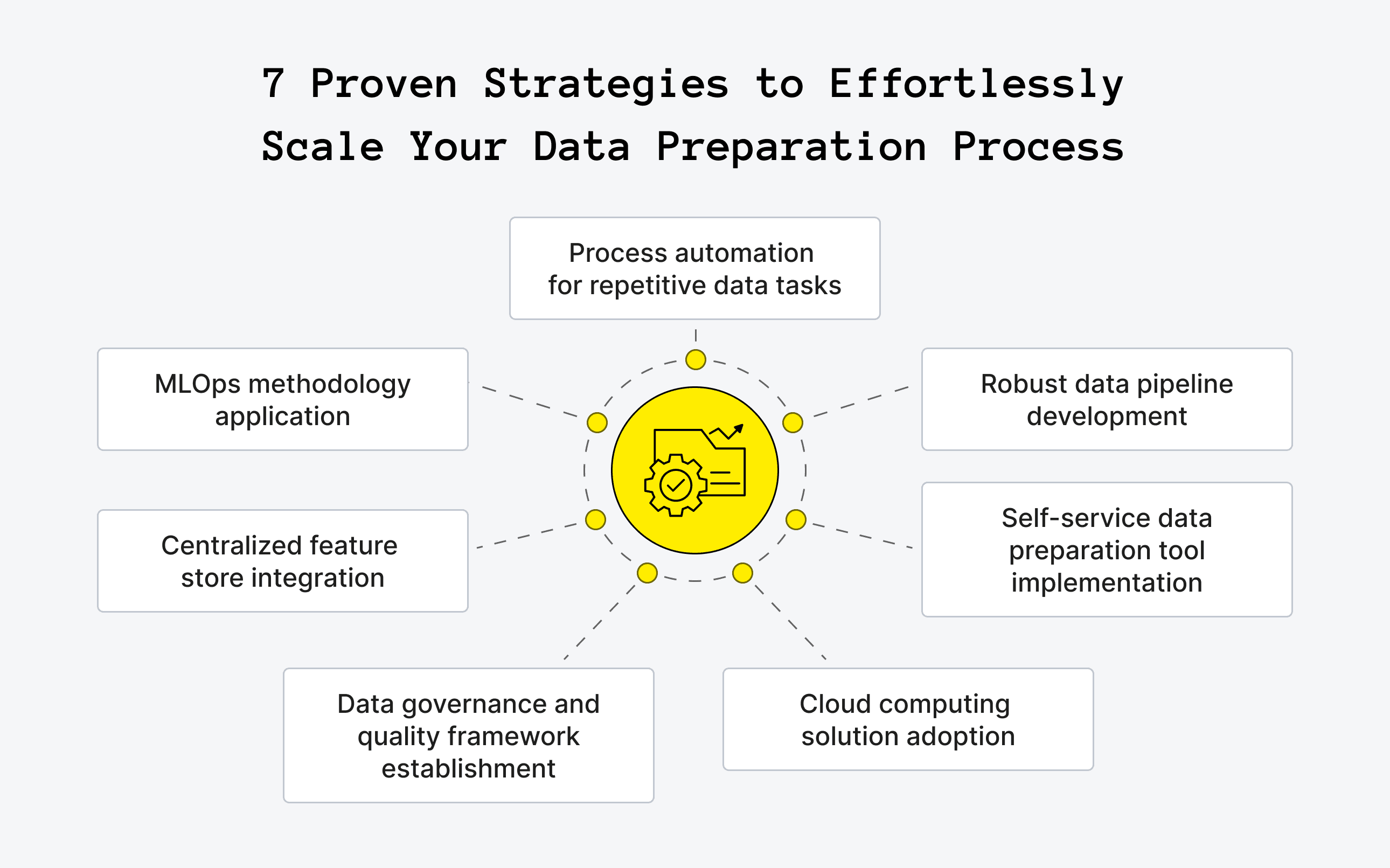
Automate Repetitive Tasks
Data preparation needs smart decisions, but the rest is just mechanics. So, identify manual and repetitive data preparation tasks, such as data cleaning, transformation, and validation, and automate them using scripts, workflows, or data prep tools.
Automation saves time and resources and reduces the risk of human errors to ensure consistency. Explore Apache Airflow, Luigi, and cloud-based ETL/ELT tools for this task.
Build Robust Data Pipelines
Efficient data pipelines will automatically ingest, process, and prepare data from various sources on a continuous basis. These pipelines should be modular, scalable, and easy to maintain.
You can use cloud-based data warehousing and processing services (AWS S3, Azure Data Lake Storage, Google Cloud Storage; AWS Glue, Azure Data Factory, Google Cloud Dataflow. These can scale resources up or down as needed.
Embrace Self-Service Data Preparation Tools
Empower data scientists and analysts with user-friendly, self-service data preparation tools to perform data cleaning, transformation, and exploration. With these tools, they won't rely on engineering teams alone.
Your team will get visual interfaces and pre-built transformations, so the process will become more accessible and efficient. Some tools to consider are Trifacta, Alteryx, and Tableau Prep (see Tableau's pricing here).
Take Advantage of Cloud Computing
Cloud platforms give you scalable storage and compute resources to handle large volumes of data and complex data preparation tasks. When you use cloud-based data lakes, data warehouses, and data processing services, you have resources to improve the scalability and cost-effectiveness of your efforts.
Implement Data Governance and Quality Frameworks
Establish clear data governance policies, data quality standards, and monitoring mechanisms to ensure the consistency, accuracy, and reliability of your prepared data at scale. The essential things to define are data ownership, data lineage, and data validation rules.
Use Feature Stores
If you have multiple AI projects, a feature store will be a valuable asset. It gives you a centralized repository for storing, managing, and serving pre-computed features, so you can reduce the need to re-engineer the same features for different models.
Feast and AWS SageMaker Feature Store are good feature store solutions.
Adopt MLOps Practices
Finally, data preparation should become a part of your broader Machine Learning Operations framework. Consider setting up version control for data preparation pipelines, automated testing of data quality and transformations, and continuous monitoring of data drift and model performance.
Seeking help with building your product?
Upsilon has an extensive talent pool made up of experts who can help bring your AI ideas to life!
Concluding Thoughts on Data Preparation for AI
Preparing your data isn’t just a technical checkbox—it’s what powers all those smart, automated features behind the scenes. When you invest in quality data from the outset, you’ll see better outcomes and avoid costly mistakes. The companies doing well with AI are the ones that set up solid data systems, keep improving how they handle data, and make data part of everyday work.
At Upsilon, we know that getting an AI project right starts with great data. But getting data into the right shape is often the hardest part of building AI. It's complex, time-consuming, and a major bottleneck for most startups.
If you’re looking for expert help, our generative AI development services can walk you through every phase—from initial data prep to a product that’s ready to launch. Ready to get started? Contact Upsilon now and let’s build something breakthrough together!
FAQ
1. What are the steps in data preparation for AI?
How to prepare data for AI is a multi-step process that can be summarized as:
- Defining your goals: Understand what you need to solve with the algorithms, what information you'll need to collect, and how to measure success.
- Data collection and assessment: Gather data from various sources and check it for relevance and completeness.
- Data cleaning: Handle errors, missing values, and inconsistencies.
- Data transformation and feature engineering: Convert raw data into a usable format, and create new, meaningful features to improve model performance.
- Data labeling: Add categories or tags to the data for supervised machine learning.
- Splitting the dataset: Split your datasets into three: training, validation, and testing (70%/15%/15%). Train your model on the biggest one, then validate its performance with the second, and make final testing on the dataset that your model has never seen before.
2. How to clean data for an AI project?
You can clean data by:
- Removing duplicates and irrelevant information.
- Handling missing values by either deleting the data points or imputing them (using the mean, median, or a specific value).
- Correcting structural errors, like typos or inconsistent formatting.
- Identifying and treating outliers that could skew your model's results. This is often the most time-consuming step in the entire process.
3. How much data is needed to train an AI model?
There’s no magic number, as it depends on several factors:
- The complexity of your problem. A simple task like classifying two types of objects needs less data than a complex one like predicting market trends.
- The model's complexity. Deep learning models, with their many parameters, need much larger datasets than traditional machine learning algorithms to avoid overfitting.
- Data quality. High-quality, clean, and representative data can reduce the amount you need.
- Transfer learning. Using a model that has already been pre-trained on a massive dataset (like a large language model) can reduce the amount of data you need to train your own custom model.
4. What tools are used for AI data preparation?
The tools you use depend on the type of data and the complexity of your project. They range from simple programming libraries to full-service platforms:
- Programming libraries: Python libraries, Pandas and NumPy, for data cleaning, scikit-learn and TensorFlow for feature engineering and model training.
- No-code/low-code tools: OpenRefine or Trifacta are great for visual data cleaning and transformation.
- Cloud-based solutions: Google Cloud AI Platform, Microsoft Azure Machine Learning, and Amazon SageMaker.



to top

-2.png)